本質を理解し、向き合い方を知らずしてデータ活用には至らない 第1回
2021.11.09

石油の時代と言われた20世紀に対して、21世紀はデータの時代と言われるほど、経営資源のヒト・モノ・カネに加えて、第四の資源としてデータが注目されるようになっています。そのような中、データについて何度も聞かれた質問があります。
「データは何の役に立つのか? 」
「データは何をもたらしてくれるのか?」
「 データを活用するにはどうしたらいいのか?」
「 データを活用してどんな効果を得ているのか?」
これら質問にはどれも共通点があります。質問で聞きたいことは、「データはどのように私たちを助けてくれるのか」ということです。多くの人がデータの重要性を説いた書籍や記事を見てはその理屈は理解できても実感としてなかなか腑に落ちず、世の中で騒がれているほど自分の中ではそこまでデータの重要性を感じないと思っている方は少なくないでしょう。それは先の質問に表されています。書籍や記事で見かける事柄は話の大きなことが取り上げられるがあまり、自分ごとにしづらく、データの恩恵が身近に感じられない、もしくは今までExcelなどでデータに触れていた人にとっては今までと何が違うのかということを抱いているからではないでしょうか。
考えるための道具としてのデータ
それはデータを答え合わせの道具として使うのではなく、考えるための道具として使うという手段が増えたことです。
従来のデータというと営業データやアンケート調査などのデータが思い浮かぶでしょう。営業データは日々の進捗を確認するために営業担当が活動した結果のデータです。アンケート調査は特定の知りたい事柄に対して調べた結果のデータです。どちらも由来は異なりますが、同じ結果データです。これらデータをその目的のまま使うとすると、営業データは営業活動の進捗を確認する、アンケート調査は調べたい事柄の状況を確認するといった使い方になりますが、どれも答え合わせとしてデータを使っています。このようなデータの使い方は自ずと多くの方が理解しやすいのではないでしょうか。私たちは皆、その扱い方を知っています。そこには解釈も何もないので、事実としての結果を把握するのみという行為をしていて、私たちは皆、それを日常的に行っていますので、慣れています。ヒトは目の前にあるもの、認識しているものは思考が走るので、こうした類の使い方であれば想像しやすく、理解もしやすいということになります。
一方、考えるための道具としてデータを使うということは何を意味しているか。例えば、新型コロナウイルス禍で良く見聞きするようになった「携帯の位置情報データ」があります。これで人流の多少が毎日のように報道されていますが、このデータは新型コロナウイルス蔓延抑制を目的に集めたデータでもなければ、人流を把握するために集められたデータでもありません。Webサイトの閲覧やアプリを使う際に通信するそのログが元になっています。つまり、何か特定の目的があって集めたデータでもなければ、使い方としてどれくらいの通信があったのか、どのようなWebサイトを閲覧する人が多いのかを確認するためにデータを活用しているわけではないのです。このように目的があって集められた結果データをそのまま扱うのと、結果集まったデータを何か別の目的で扱うのとではデータが果たす役割に大きく特徴が異なります。
Variety・Velocity・Volumeが必要なわけ
ある事象を理解するためにヒトが思考する際には事象を構成する要素に分解したり、要素間を比較したりしてその特徴の違いをもって、ヒトは思考し、事象の多少、変化の有無などの言及をします。そのため、量が多いということは事象の分解・比較をして思考するための前提条件ともいえます。
ヒトは目の前にあるもの、認識しているものに思考が走ると言いましたが、逆を言えば従来目の前にあるもの、認識しているものの範囲でしかデータを集められず、扱えていなかったところがあります。それがデータを蓄積するサーバコストが格段に安くなり、技術進歩があり、集められるデータは集めようという動きが出てきたとともに、データ提供やデータ活用ツールが増えてきました。これにより集めたデータを扱える人が増え、ヒトが認識範囲外の事柄もとらえて、新しい視点、新しい気づきをデータから得られるという期待を多くの人が持ち始めたというのが現在地ではないでしょうか。
データを扱うには前処理が8割と言われるのはなぜか
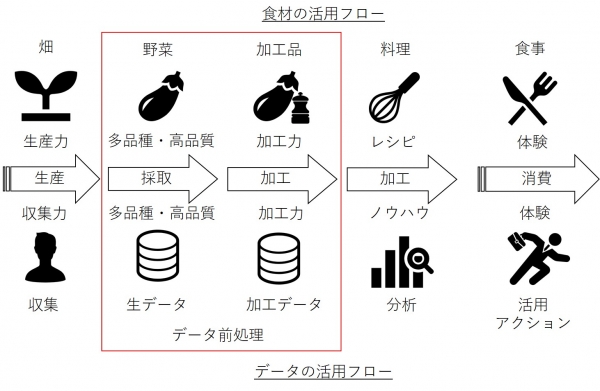
図1 データ活用と食材活用の対照フローイメージ
アンケート調査データのような、もともと目的ありきで集められた結果データをそのまま扱うのであれば、もともと集計も想定したデータの記録の仕方が設定されているので、前処理という工程はほとんど必要なく、記録されたデータを単純集計することができる場合がほとんどです。しかし、データを異なる目的で扱う場合は、その集計・分析したい目的に合わせて、データの在り方が異なることが多いです。また、他社のデータと自社のデータを統合するといった複数種のデータを統合するといった場合も、統合前のそれぞれのデータは統合することを前提にしたデータではないので、統合するためのデータ前処理が発生するといった具合です。この場合は、データ前処理のために統合するためのキーとなるデータも同時に必要になってきます。
データという直接的なもので考えるとわかりづらいかもしれませんが、要は料理と同様です。野菜や果物をそのまま食べる分には皮をむく程度で、そのまま食べられますが、おいしく食べやすい料理にしたいとあれば、食材に味付けをして、食べやすさに合わせて刻み方を変えたりして調理する工程が発生します。データ前処理とはそのような目的に合わせて行う作業だと思えば理解しやすいと思います。そう考えれば、料理の下ごしらえや調理に時間がかかるのは当然という考えに至るのと同様に、データを扱うということも目的やその難易度が異なればそれに合わせて時間をかけることになります。もとの食材から完成形の料理とのギャップが大きければ大きいほど手間がかかるように、目的を達成するために元データがそれに沿ったデータ構造でなければないほど、目的達成のためにかかる工数は大きくなります。また分析という行為は必ずしも1回だけで思い通りのことができるとは限りません。仮説を立ててその仮説に基づいてデータ前処理をしますが、分析結果から改めて別の仮説を立てたり、そもそも仮説が間違っていたりする場合などは、その仮説検証の繰り返す分だけ工数はかかり、よりよい分析、アウトプットの精度向上などを目指せば自ずとデータ前処理の数が多くなりがちです。
データ分析し、施策まで検討するといってもより精度を高めようとすると分析とデータ前処理を複数繰り返しながら、ようやく施策検討の精度を高めていけますので、実際は工数の残り2割程度では足りず、課題になりがちな部分です。ゆえに、データ分析能力となると、高度な分析ロジックなどに目が向きがちですが、いかに繰り返し精度を高めるアクションが取れるか、そのための分析とデータ前処理のスピードを上げられるかが問われてきますので、分析能力は前処理能力や前処理工数が少なくて済む構造化データを保持しているのかに加え、素早くデータの前処処理ができるのか、そして高速に繰り返し行為ができるのかも重要な要素として位置付けられます。
データがヒトに知覚レベルを引き上げる恩恵をもたらす
ヒトが見聞きできる範囲をわざわざデータで再確認する必要はありません。しかし、見聞きできない範囲はデータで補うことで、物事の骨格を理解し、その枠組みをもとに仮説立てや推察など思考を走らせます。データ分析というのも、言い換えれば「データを用いて様々な観点で比較し、特徴を洗い出す」作業といえます。企業1社の業績が10億円だったとき、その1社だけを知っていてもその業績規模が大きいのか、順調なのかはわかりませんが、別の会社が1億円であったら、当然比較企業に比べると10億円の企業は大きいことがうかがえます。ただ、この比較もたった1社だけしか見ていないので、たまたま比較対象が小さかっただけかもしれません。なので、10億円の企業と同じ業種で比較してみる、創業年代が同じ企業と比較してみるといったことをして、それでも10億円の企業が少なければ、その企業は規模が大きいという判断をすることができます。
データ分析というと難しく感じますが、ヒトは何かを判断、評価する際には何かしら比較をしていて、いわゆる分析作業を日常的にしています。さきほどの企業業績の良し悪しを判断したり、新規取引を結ぶか否か判断したりするのも何かしらの比較をもとに決定しているはずです。仮にデータがない場合は、自分の知っている企業と比較するしかありませんので、大企業ばかりしか知らない人は10億円企業が小さすぎると判断してしまうかもしれません。こうしたことは言われると当たり前に思えますが、地方創生の文脈では「KKO(勘、経験、思い込み)」として課題視されるほど、日常的に起きている事柄だと思います。ちなみに、99%が中小企業である日本企業の全体像をTDBデータで確認すると、売上高の平均値は約24億円、中央値は1億円弱という結果でした。平均値と中央値の乖離が大きいのは、日本企業のうち大規模企業は極僅かでその一部の企業に値が引っ張られて平均値が高く出ています。日本企業の代表的な企業規模というと1億円程度であり、10億円となるとある程度大きい企業であることが言えます。これと似た例は日本の平均賃金でも同じ話があります。全体を知っているとこのように目の前にするデータの評価もしやすくなるわけです。これはいわば、データによってヒトの「知覚レベル」を引き上げ、思考の幅や思考の仕方、思考の結果の判断軸が新たに加わることによって、意思決定や判断、行動が変わるということを意味します。つまり、データとうまく向き合うことでヒトが普段知覚している狭い範囲を拡張し、広く事物を見分け、捉えることによって偏った思考を補正し、比較や判断できる幅を広げられるようになるということです。
データと意思・目的の両輪がデータとの向き合い方のカギとなる
一方、データなき文脈もまた意味はありそうに思えますが、その実態が現実を帯びているものなのか、虚像にすぎないものなのかわからず、意味に実態が伴いません。実態が伴わないものには、ヒトの想像や解釈が無限大の幅を持ち得るため、どれが意味あるものなのかがわからぬまま錯綜するだけになります。そのため、情報というものを扱い、ヒトが知覚できるものを広げ、視野狭窄に陥らずに思考を進めるためには、「データと意思・目的の両輪が重要」になります。
データの時代といわれるようになると、「データで何でもわかるのではないか」という漠然と過度な期待を持つ方がいます。先にも述べましたが、データと情報は分けて考えた方が良いです。データはシグナルとして位置づけ、そこに意味づけするのはヒトの役割です。データVS経験という文脈の対立構造で語ったり、ロボットVSヒトといった記事があったりしますが、データと経験よる知見は対立構造ではなく、補完関係で考えるべきでロボットとヒトも同様です。データはヒトの知覚レベルを引き上げるといいましたが、知覚できる範囲を拡張して対象の事物を比較・分析することで偏った自分の認識を補完する形で全体像を理解し、個と全体の関係を整理し、全体の骨格を理解したうえで、ヒトが経験などで得た様々な背景や解釈をもとにデータに肉付けして、情報として成立させるといった向き合い方が望ましいでしょう。そう考えていくと、ヒトがなぜデータリテラシーを身に着けるとよいのかも自ずと理解しやすいかと思います。
一つは、「非連続な思考」ができるようにすることです。勘や経験というものからの思考は自分が見聞きした範囲でしか物事の判断をすることができません。それは現在地にある課題へのカイゼンをする場合には、有意義に働きます。一方、新しい問題提起やそもそも自分が見聞きしていない範囲の新しい発想や課題創出を必要とする場合では、自分以外の新しいなにかが必要となります。そこにデータは寄与してくれます。データドリブンの取り組みはまさにこの話です。先に述べてきた全体俯瞰という話もこの部類に入るのではないかと思います。自分が見ている連続的な情報からはどんなに頑張っても全体までたどり着くことは難しいです。
もう一つは、「共通言語」です。一個人の勘や経験はあくまでその人が見聞きしてきた情報をもとに形成された知であります。その知を形成するためには多くのバックグラウンドが影響していると思います。この勘や経験に基づいて議論するというのはとても難しいことです。なぜなら、一個人の勘や経験は他者にとっての当たり前ではなく、議論の前提に置きづらいものだからです。それゆえに「私の経験ではこう思う」「私は別でこう思う」と結局のところ、議論がかみ合うことが難しいことがおきます。そのような場面、とはいえ皆さん大人ですし、良くも悪くも物分かりがよく、かつ何かしら限られた時間内で収束しないといけないということがあれば、議論の決め方はどの人の勘や経験をよりどころにするか、つまり誰の勘や経験を大事にするかという意思決定の仕方になるでしょう。
そうした議論や意思決定の限界に対して、データは共通言語として、議論の羅針盤としてのよりどころになりえます。勘や経験だけだったら、根拠のない決めの世界でよりどころを決めなくてはいけないので、納得感のある、声の大きい人、有名な人、過去の実績からあたりが良さそうな人という本質とは異なるところで決めてしまいがちです。これが問題になるのは論点がずれてしまうことだけでなく、意思決定の根拠が曖昧となり、その曖昧な部分を誰かに委ねることで責任の所在も不明瞭となり、議論が次第に他人事になってしまうことにあります。
データを活用する場合はデータで選ばれるというよりはデータが中立的な立場としてその場に判断基準を設けることで、ヒトの意思決定の方法に変化をもたらします。ただし、決して勘や経験を否定すべきということではありません。データにも限界があるように、勘や経験にも限界があり、それらの限界領域は異なるため、お互い相互補完関係にあるといえます。そのため、どちらか一方に偏るのではなく、どちらもその得意領域を活用することによってメリットを享受しやすくなります。
よくあるデータVS経験といったバーサス構造の議論に意味はありません。
最後に「共有知」のしやすさです。知的資産経営には「人的資産」「構造資産」「関係資産」の3つに分けて、財務諸表には表れてこない目に見えにくい経営資源を分類します。このうち人的資産とは、従業員が退職する際に持ち出される資産で、人に帰属するノウハウや経験はその例です。構造資産は従業員が退職しても組織に残る資産で、データベースや仕組みなどが挙げられます。勘や経験というのはこの人的資産に当たり、人に帰属するがゆえに暗黙知になりやすく、共有しづらさがあります。一方で自然法則や、ヒトの行動などデータとなりえる事象を情報として、またはデータとして存在させることによって、人的資産になりそうな部分も構造資産として組織に残し、組織内に共有することができます。データは、個人が得た情報をデータという形となって存在することによって、ヒトが直接見聞きせずとも、知を共有することで代理体験的に得られる情報になるわけです。別の言い方をするならば、勘や経験は第三者参照が難しい情報、データは第三者参照ができる情報として位置付けることができると思います。伝播性の高さは諸刃の剣的なところはありますが、データの強みであることは確かです。
執筆:企総部企画課 六信 孝則
<バックナンバー>
第1回 なぜデータが今そこまで注目されるのか(本コラム)
第2回 目的なき文脈を避けるための目的の特定方法
第3回 データ社会の今後期待される2つのこと
第4回 本質を理解し、向き合い方を知らずしてデータ活用には至らない